
ZenML- A Great Tool For Standardizing Data Science Workflows
By Rahul Toora | photo by Solen Feyissa on Unsplash
A few months ago, the Debt and CLV Data Science teams got together at our office in the Interchange, Croydon to partake in a hackathon. The purpose of the hackathon was to try out Apache Airflow and ZenML as open-source tools to improve MLOps workflows. I will be detailing the findings from ZenML here.
ZenML is a great tool that allows you to transform Python functions into chained steps forming reproducible ML pipelines. This is done using Python decorators. Each step can represent a different part of the ML lifecycle: importing data, pre-processing, model training, etc. Steps are entirely customizable allowing great flexibility in your implementation. The debt team experimented with creating a pipeline from a simple iteration of our PAYG Financial vulnerability clustering model. This model uses Pandas and scikit-learn KMeans clustering (still to test if pure PySpark can be used).
In less than an hour, the team was able to put together a working pipeline, using the ZenML functional API, that looked something like this:
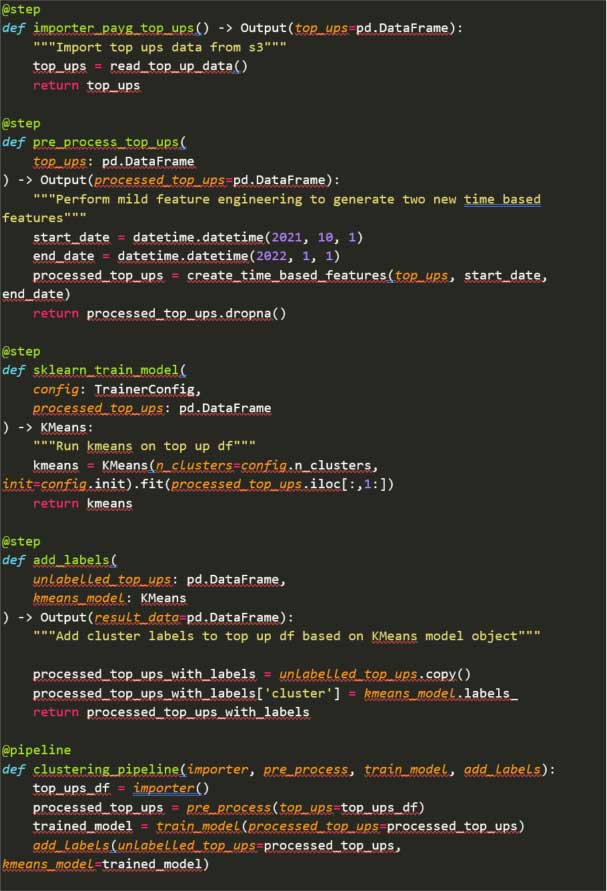
We were able to trigger the pipeline manually (although ZenML has job scheduling capabilities) from within a jupyter notebook using the following code:
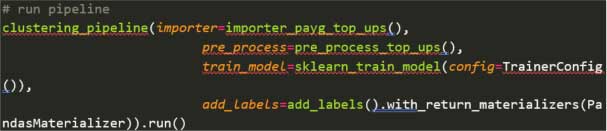
The first thing to notice is how the pipeline offers a very simple and clear way to represent steps in your ML lifecycle. ZenML uses default caching so debugging or testing experiment pipeline iterations is very quick. What impressed us the most was how quick it was to remove and add steps.
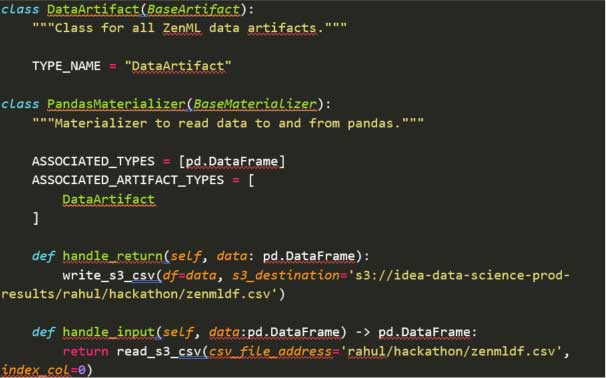
We also created a custom Materializer Class that enabled us to store any result pandas DataFrame artifacts directly to S3 (however many other cloud storage solutions could be used):
Although we did not have time to test this: Feature Stores, Model Registries, Experiment Trackers and more can be integrated within a ZenML workflow due to its expanding list of third-party integrations. This gives Data Scientists the power to choose the best tooling and infrastructure for their specific use case.
To conclude, ZenML is a great tool for standardizing data science workflows and makes creating ML pipelines simple and reproducible.
Related articles

EDF's Open Tariff APIs

